https://docs.aws.amazon.com/lambda/latest/dg/welcome.html
Lambdaとは
AWS Lambdaは、サーバーの用意や管理なしでコードを実行できるサービスです。コードを「関数(Lambda関数)」として登録し、必要なときだけ自動的に実行・スケール。
How Lambda works
Lambda関数を書くために必要な、4つの重要な要素
- Lambda functions and function handlers
- functions
- イベントに応じて自動で実行される、小さな独立したプログラム
- イベント駆動
- コードは自己完結、特定の処理を1つだけ担当する(単一責任)
- 実行が終わると自動的に停止する
- 関数コードと依存関係は「デプロイパッケージ」としてまとめる
- .zip アーカイブ形式 または コンテナイメージ形式が使える
- function handlers
- eventsを処理するmethod
- Lambda が関数を実行する際に呼び出される
- イベントに関するデータが引数として渡される
- Lambda関数ごとに1つのハンドラーのみ定義できる
- functions
- Lambda execution environment and runtimes
- execution environment
- 独立しており、secure(安全)な環境で動作する
- function の実行に必要な processes や resources を管理する
- 初回実行時に新しい実行環境を作成する
- 実行終了後もすぐには環境を破棄せず、一時的に保持する
- 再実行時には、既存の実行環境を再利用(re-use)する可能性がある
- runtime
- 実行環境に含まれる、言語ごとのランタイム環境
- Lambda 本体と関数コードの間で、イベントの受け渡しとレスポンスの中継を行う
- Supported runtimes
- マネージド runtime 使用時は、Lambda がセキュリティアップデートやパッチを自動適用する
- execution environment
- Events and triggers
- Events
- Lambda 関数は event によって起動される
- Event は、他の AWS サービスから発生する特定のアクション
- Lambda は event data を JSON document として受け取り、runtime がそれをオブジェクトに変換して handler に渡す
- Triggers
- Trigger は function と event source を connect する仕組み
- Lambda 関数には複数の triggers を設定可能
- 一部のサービス(例:Amazon Kinesis、Amazon SQS)は trigger ではなく event source mapping を使用する
- Polling によってデータを取得し、batch 化して関数を呼び出す
- Events
- Lambda permissions and roles
- permissionsは2種類ある
- Lambda function が他の AWS サービスを使うための permissions
- Lambda service principal
lambda.amazonaws.comに対して、trusted することで Lambda がその IAM ロール(実行ロール)をsts:AssumeRoleできるようにする必要がある- 公式Defining Lambda function permissions with an execution role
- 関数のコード中でわざわざ sts.assumeRole() を書くなという意味
- Lambda service principal
- 他のユーザーや AWS サービスが Lambda を呼び出すための permissions
- AWSの他のServiceからLambda 関数に対して、何かしら操作したい場合は、リソースベースポリシーを設定する必要がある
- 公式Viewing resource-based IAM policies in Lambda
- 例えば、lambdaを実行させたい場合は、
"Action": "lambda:InvokeFunction"を宣言する必要がある
- AWSの他のServiceからLambda 関数に対して、何かしら操作したい場合は、リソースベースポリシーを設定する必要がある
- Lambda function が他の AWS サービスを使うための permissions
- permissionsは2種類ある
Running code
The Lambda execution model
| フェーズ名 | 内容 | 詳細説明 |
|---|---|---|
| 1. Initialization (初期化) | 実行環境の準備 | - Lambdaが実行環境を作成 - ランタイムのセットアップ - コードの読み込み - スタートアップコードの実行(例:グローバル領域でのDB接続など) |
| 2. Invocation (呼び出し) | 関数の実行 | - イベントを受け取るとこの環境で関数を実行 - 複数のイベントを同じ環境で順番に処理可能 - イベント数が増えると環境を追加作成 - 減れば不要な環境を停止 |
| 3. Shutdown (終了) | 後片付けと終了処理 | - Lambdaが環境を削除する前に、残りの処理を片付ける時間(チャンス)が与えられる - 例:一時ファイルの削除、接続のクローズなど |
- メモリと
/tmpストレージ- 関数には設定したメモリと、512MBの一時保存領域(
/tmp)が提供される。
- 関数には設定したメモリと、512MBの一時保存領域(
- リソースの再利用
- DB接続やクライアントなどを、関数呼び出し間で使い回せる(同じ環境が再利用されるため)。
- Provisioned Concurrency(事前起動)
- リクエストに即時応答するために、実行環境を事前に起動しておく機能。
programming model
- Lambda関数のエントリーポイントは ハンドラー関数 として指定される。イベント情報とコンテキスト(リクエストIDなど)が引数として渡される。
- ハンドラーの外側(モジュールスコープやクラスのstatic・インスタンスフィールド)で初期化された変数やオブジェクトは、実行環境が再利用される限り保持される。
- 初期化処理の中で、AWS SDKクライアントなどのリソースを生成しておくと、後の呼び出しで高速に再利用できる。
/tmpディレクトリは512MBの一時ストレージとして使用でき、複数の呼び出し間で使える可能性がある。- Lambdaはイベントを順不同または並列で処理する可能性があるため、関数インスタンスの永続性に依存しない設計が必要。
Lambda execution environment lifecycle
Lambdaの実行環境は、「Runtime + Function」と「Extension」で構成されており、それぞれが専用のAPI(Runtime API / Extensions API / Telemetry API)を使ってLambdaと通信します。
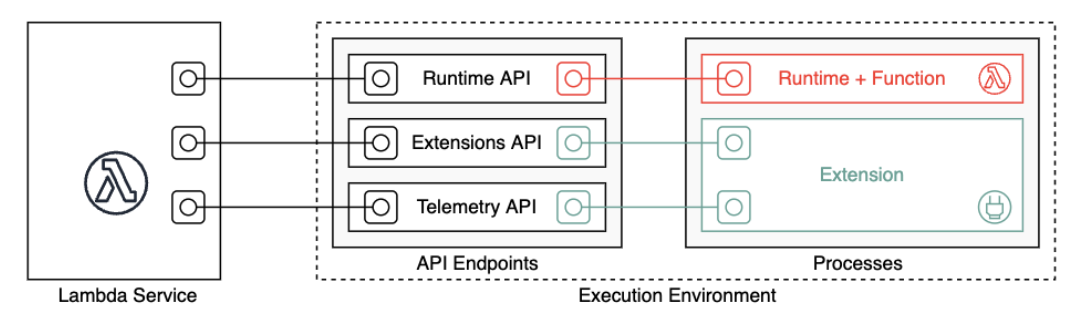
lifecycle

phaseは3つが存在する。
- INIT
- INVOKE
- SHUTDOWN
詳しく入る前に知っておきたいこと
各PhaseはLambdaからruntimeと全てのextensionに各種event(INIT、INVOKE、SHUTDOWN)を送信します。
runtimeやextensionはそのeventの処理が完了したらそれぞれのAPIに対してNext API requestしてeventの処理が完了したことを通知します。
runtimeと各extensionが完了し、かつ保留中のイベントがない場合、Lambdaは実行環境をフリーズし、次のフェーズ(INVOKE か SHUTDOWN)のEventが来るまで待機状態に入ります。
Init phase
Init phaseでは以下のタスクが実行されます。
- Start all extensions (Extension init)
- Bootstrap the runtime (Runtime init)
- Run the function’s static code (Function init)
- Run any before-checkpoint runtime hooks (Lambda SnapStart のみ)
まとめ
- Initフェーズのタイムアウト (通常):
- Initフェーズは、上記タスク(SnapStartでない場合は3つ)を10秒以内に完了させる必要があります。
- 10秒以内に完了しなかった場合、Lambdaは最初の関数呼び出し時に Initフェーズを再試行します。この再試行されるInitフェーズと、それに続くInvokeフェーズが、設定された関数のタイムアウト時間内で実行される必要があります。
- (修正前:「Init+INVOKE合わせて、function timeoutで設定した時間以内で実行します。」)
- Initフェーズのタイムアウト (Provisioned Concurrency または SnapStart の場合):
- Provisioned Concurrency または SnapStart を使用する関数の場合、Initフェーズの10秒タイムアウトは適用されません。
- 初期化コードは最大15分間実行できます。具体的なタイムアウトは、130秒または設定された関数タイムアウト(最大900秒)のいずれか高い方となります。
- Lambda SnapStart を使うと:
- Initフェーズは、関数バージョンを発行する時に実行されます。Lambda は初期化された実行環境のメモリとディスク状態のスナップショットを保存し、暗号化して永続化、低レイテンシアクセスのためにキャッシュします。
before-checkpointruntime hook があれば、Initフェーズの最後に実行されます。- Restore phase (Lambda SnapStart のみ):
- 関数が初めて呼び出されたりスケールアップしたりする際には、Lambda は新しい実行環境を最初から初期化するのではなく、永続化されたスナップショットから復元します。
after-restore runtime hookがあれば、Restoreフェーズの最後に実行されます。- この
after-restore runtime hookの実行時間は課金対象になります。 - ランタイムのロードと
after-restore runtime hookの実行は、合計10秒以内に完了する必要があります。 - 間に合わない場合は、
SnapStartTimeoutExceptionがスローされ、リクエストが失敗します。 - Restoreフェーズが完了すると、次は Invokeフェーズ に進みます。
- Provisioned Concurrency (PC) を使うと:
- コールドスタートをほぼ完全に排除することができます。LambdaはPC設定時に実行環境を初期化し、呼び出しに備えて常に利用可能な状態を維持します。
- 初期化済みの環境であっても、初回呼び出し時にランタイムやメモリ設定に応じて可変のレイテンシ(遅延)が発生する可能性があります。
- 関数呼び出しと初期化フェーズの間に時間的なギャップが見られることがあります。
💡 runtime hook (Lambda SnapStart の場合) とは: Lambda SnapStart のライフサイクルにおいて、開発者が特定のポイント(チェックポイント作成前やスナップショット復元後)で任意の処理(コード)を挿入できる仕組みです。 (修正前:「Lambda が関数を実行する前後に、開発者が任意の処理(コード)を挿入できる仕組みです。」これは一般的な説明であり、SnapStartの文脈に合わせて具体化しました。)
Invoke phase
まとめ
- function’s timeoutはInvoke phas全体に対して適用されます。
- 後処理(post-invoke)は存在しない。
- duration time = runtime time + extensions time で求められる
Shutdown phase
まとめ
- Duration limit(シャットダウン処理の制限時間):
- 拡張機能(Extensions)の登録状況によって、シャットダウンに与えられる時間が異なります。
- 拡張機能なし: 0ms (即時破棄)
- 内部拡張機能あり: 500ms
- 外部拡張機能あり: 2000ms (2秒)
- この制限時間内に処理が完了しない場合、Lambdaは
SIGKILLシグナルを使ってプロセスを強制終了させます。
- 拡張機能(Extensions)の登録状況によって、シャットダウンに与えられる時間が異なります。
- 定期的な実行環境の終了:
- ランタイムのアップデートやメンテナンスのため、Lambdaの実行環境は数時間ごとに終了されます 。
- これは、継続的に呼び出されているLambda関数であっても同様です。
Cold starts and latency
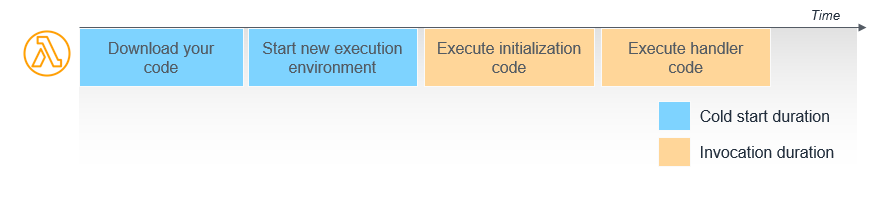
Lambda関数を実行する際には、実行までに以下の4つのステップがある。
- Download your code
- Start new execution environment
- Execute initialization code(Init phase)
- Execute handler code(Invoke phase)
Step1と2が「Cold Start」と呼ばれる準備時間
Step3と4が実際の関数の実行時間(Invocation)
- Cold Start(コールドスタート)
- Lambda関数の初回実行時や、長時間使用されていなかった関数の再実行時に発生する。
- コードのダウンロードや実行環境のセットアップに時間がかかる。
- この準備時間は課金対象外だが、呼び出し全体の遅延(レイテンシ)を引き起こす。
- Cold Startの所要時間は、通常100ミリ秒未満から1秒以上に及ぶこともある。
- Warm Start(ウォームスタート)
- すでに初期化済みのLambda実行環境が再利用される状態。
- 実行環境がすでに構築されているため、次のリクエスト処理は高速に完了する。
- 初回実行後、Lambdaは実行環境を一時的に保持・凍結し、後続のリクエストで再利用することで発生する。
Optimizing static initialization
- 静的初期化は、
lambda_handlerコードが関数内で実行を開始する前に起こります。lambda_handlerのスコープ外で定義されたコード(静的初期化コード)は、新しい実行環境が作成される際(コールドスタート時)に一度だけ実行されます。ウォームスタート時には再実行されません。
- initialization codeは、関数実行前(init phase)のレイテンシにおける最大の要因となります。
- initialization codeのレイテンシに影響を与える要素:
- Lambdaレイヤーを含む、インポートされるライブラリや依存関係の観点から見た関数パッケージのサイズ。
- コードの量と初期化処理の作業量。
- 接続やその他のリソースをセットアップする際の、ライブラリや他のサービスのパフォーマンス。
- なるべく関数の役割は小さく、コード量を減らす
- またはLazy Load(遅延ロード)使って、init phaseを短くすることもできる。考えて使って
- 必要なライブラリのみをインポートする(例: aws-sdk/clients/dynamodbのように特定のクライアントだけを読み込む)
- 呼び出しごとにリセットされるようなコンテキスト固有の情報はグローバル変数に置かない
Creating event-driven architectures with Lambda
Lambdaの実行には2つの方法がある。
| 型 | 説明 | 例 |
|---|---|---|
| Push | AWSサービスがイベントを直接送信(push)してLambdaを起動する | API Gateway、S3、EventBridge |
| Pull | Lambdaが自分で定期的にチェック(polling)してイベントがあれば処理する | SQS、DynamoDB Streams、Kinesis |
functionにpassされるeventはJson形式のデータです。Jsonの構造は依存するServiceに依存する。 invoke phaseは最大15分まで実行できるけど、Lambdaは1秒以下invoke phase(handler関数の実行時間)終了することがベスト
eventsを使うことのメリット
Polling / Webhook の課題
- Polling
- 新しいデータ取得にラグがある
- 無駄なリクエストが多く非効率(CPU・帯域を浪費)
- Webhook
- 他マイクロサービスが対応していないケースあり
- 認証・認可の仕組みが必要になることが多い
- 共通の課題
- オンデマンドスケーリングが難しい
- スケール対応には開発者による追加実装が必要
イベント駆動アーキテクチャの利点
- イベントによる置き換え
- Polling / Webhook を使わずにイベントで処理を通知
- イベントはフィルタ・ルーティング・プッシュが可能
- 効率性・コスト削減
- 帯域とCPU使用量を抑えられる可能性
- 結果としてコスト削減も見込める
- 構成の簡素化
- 各機能が小さく、コード量も少ない
- ニアリアルタイム対応
- アプリケーションの状態が変化するとすぐにイベントが生成される
- バッチ処理への依存を減らせます
- スケーラビリティ
- カスタムコードを変えずにLambdaによりスケールはサービス側で自動対応
Improving scalability and extensibility
- マイクロサービスは、Amazon SNS や Amazon SQS にイベントを発行する。
- これらは「弾力的なバッファ」として機能し、トラフィック増加時のスケーラビリティを向上させる。
- Amazon EventBridge により、イベントの内容に基づいてフィルタリングおよびルーティングが可能。
- ルールに基づいた柔軟なメッセージ制御が実現される。
- 【スケーラビリティの利点】
- イベントベースのアーキテクチャは、モノリスに比べてスケーラブル。
- 各サービスが疎結合のため、冗長性や耐障害性が高まる。
- 【拡張性の利点】
- 他チームが既存サービスに影響を与えず機能追加可能。
- EventBridge により、将来的なイベントコンシューマーも容易に統合可能。
- 【疎結合のメリット】
- イベントの送信元は、受信側の存在や実装を意識する必要がない。
- マイクロサービスごとのロジックが単純になり、保守・運用が容易になる。
Trade-offs of event-driven architectures
Variable latency
- モノリシックアプリケーションは、同一メモリ空間内で処理されるため、レイテンシーが低く一貫性のあるパフォーマンスが期待できる。。
- イベント駆動アーキテクチャはネットワーク越しに通信するため、可変レイテンシー(Variable latency)が発生する。
- レイテンシー最小化の工夫は可能だが、モノリスの方が低レイテンシーに最適化しやすい。
- ただし、その分スケーラビリティと可用性は制限されやすい。
- 常に低レイテンシーが求められる処理(例:高頻度取引、ロボティクス自動化)には、イベント駆動は不向き。
Eventual consistency
- イベントは「状態の変化」を表す
- 多数のイベントが並行して処理されるため、結果整合性となるケースが多い
- → トランザクション処理や重複排除、全体状態の把握が難しくなる
【強整合性と結果整合性の例】
- 結果整合性:1時間あたりの注文総数
- 強整合性:現在の在庫数
【強整合性を実現するアーキテクチャ例】
- DynamoDB:
- 強整合性リード可能(高レイテンシー・高スループットになる可能性あり)
- トランザクション対応でデータ整合性を保つ
- RDS:
- ACID特性が必要な処理に向いている
- スケーラビリティはNoSQLより劣る
- RDS Proxy で Lambda などからの接続制御が可能
【バッチ処理 vs イベント処理】
- イベントベースは1件ずつ処理する設計が一般的
- サーバーレスではバッチよりリアルタイム処理が好まれる
- 小さな更新の積み重ねで処理することで可用性・スケーラビリティが向上
- 反面、イベント同士の関連性を追うのが難しくなる
Returning values to callers
- イベントベースのアプリケーションは非同期的であり、呼び出し元サービスは処理完了を待たずに他の作業を続行する
- 非同期性はスケーラビリティと柔軟性を実現するイベント駆動アーキテクチャの核心的特徴
- 同期処理に比べ、ワークフローの結果や戻り値を伝搬する仕組みは複雑になる
- 本番環境の多くの Lambda 呼び出しは Amazon S3 や Amazon SQS などのイベントトリガーによる非同期実行
- 非同期実行では「戻り値」を返すよりも、イベント処理の成功/失敗を適切に捉えることが重要
- Lambda のデッドレターキュー(DLQ)機能を使えば、失敗したイベントを特定して再試行でき、呼び出し元への通知は不要で耐障害性を高められる
Debugging across services and functions
- イベント駆動システムでは、複数サービスの状態を一度に記録・再現することが難しく、エラー発生時の原因追跡が複雑になる
- 各サービス/関数呼び出しが個別のログを持つため、特定のイベントで何が起きたかを把握しにくい
デバッグ手法構築の3要件
- 堅牢なログ収集:Amazon CloudWatch を活用し、全サービス・Lambda 関数のログを一元的に取得・保存
- トランザクション識別子の付与:全イベントに一意のトランザクション ID を付け、処理の各ステップでログに出力
- ログ解析の自動化:AWS X-Ray などのデバッグ・モニタリングサービスを使い、複数 Lambda 呼び出しやサービス横断でログを集約・解析し、根本原因の特定を容易化
Anti-patterns in Lambda-based event-driven applications
- The Lambda monolith
- 1つのLambdaでAPIを全部捌こうとする考え
- Recursive patterns that cause run-away Lambda functions
- Eventによる再起処理が走ってしまう考慮不足?
- これ面白い
- S3をTriggerでFunctionが動くけど、そのFunction内でS3を更新するからまた自身のFunctionが呼び出されるという無限ループ
- バケットを分けるやら、フォルダをイベント発行用と書き込み用に分けるやらして対処するのがいいのかな、
- SQS/SNSも同様のパターンがあるらしい、Exponential Backoff以外、自分自身を呼び出すことはないと思うけどね
- Eventによる再起処理が走ってしまう考慮不足?
- Lambda functions calling Lambda functions
- Lambdaから別のLambdaを呼びまくる考え
- SNS,SQSを通じて呼び出すが吉
- Lambdaから別のLambdaを呼びまくる考え
- Synchronous waiting within a single Lambda function
- 他のサービスを1つのFunction内でそれぞれ呼ぶこと
- 例えば、S3へのPutとDynamoDBへのWrite処理
- 「S3への書き込みとDynamoDBへの書き込みを分離する」というアーキテクチャは、処理が完全に独立している場合にのみ有効な理想論な気がする
- 例えば、S3へのPutとDynamoDBへのWrite処理
- 他のサービスを1つのFunction内でそれぞれ呼ぶこと
Reuse connections with keep-alive
- TCPコネクションを再利用(keep-alive)することで、毎回の新規接続にかかるコスト(latency, CPU)を削減できる。
- 毎回新しくTCPコネクションを張るのはオーバーヘッドが大きく、レイテンシ悪化の原因になる。
- しかし、AWS Lambdaはアイドル状態のときにコネクションを自動でクローズするため、再利用前提でコードを書いていると例外が発生することがある。
- そのため、明示的にkeep-alive有効のHTTPエージェントを設定する必要がある。
import { DynamoDBClient } from "@aws-sdk/client-dynamodb";
import { NodeHttpHandler } from "@smithy/node-http-handler";
import { Agent } from "https";
const dynamodbClient = new DynamoDBClient({
requestHandler: new NodeHttpHandler({
httpsAgent: new Agent({ keepAlive: true })
})
});
Performance testing your Lambda function
cloudwatchでfunctionが使用したmemoryを確認できる。Max Memory Used
REPORT RequestId: 3604209a-e9a3-11e6-939a-754dd98c7be3 Duration: 12.34 ms Billed Duration: 100 ms Memory Size: 128 MB Max Memory Used: 18 MB
Be familiar with Lambda quotas
- 実行時間(Execution Timeout)
- 最大 15 分(900 秒)/ 1 回の関数実行
- メモリ(Memory)
- 最小: 128 MB
- 最大: 10,240 MB(10 GB)
- ペイロードサイズ(Payload Size)
- 同期リクエスト/レスポンス:各 6 MB
- ストリームレスポンス:最大 20 MB
- 非同期呼び出し:256 KB
- リクエスト行 + ヘッダー:合計 1 MB
- ファイルディスクリプタ(File Descriptors)
- OSがファイル・ソケットを識別するための番号
- Lambda 実行環境では 1 プロセスあたり最大 1,024 個
- /tmp ストレージ
- 最低 512 MB、最大 10,240 MB(10 GB)
公式ドキュメントリンク
If you are using Amazon Simple Queue Service
SQS をイベントソースとして使う場合は、Lambda の実行時間(Timeout)が SQS の Visibility Timeout を超えないように設定してね」

